publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2023




2022

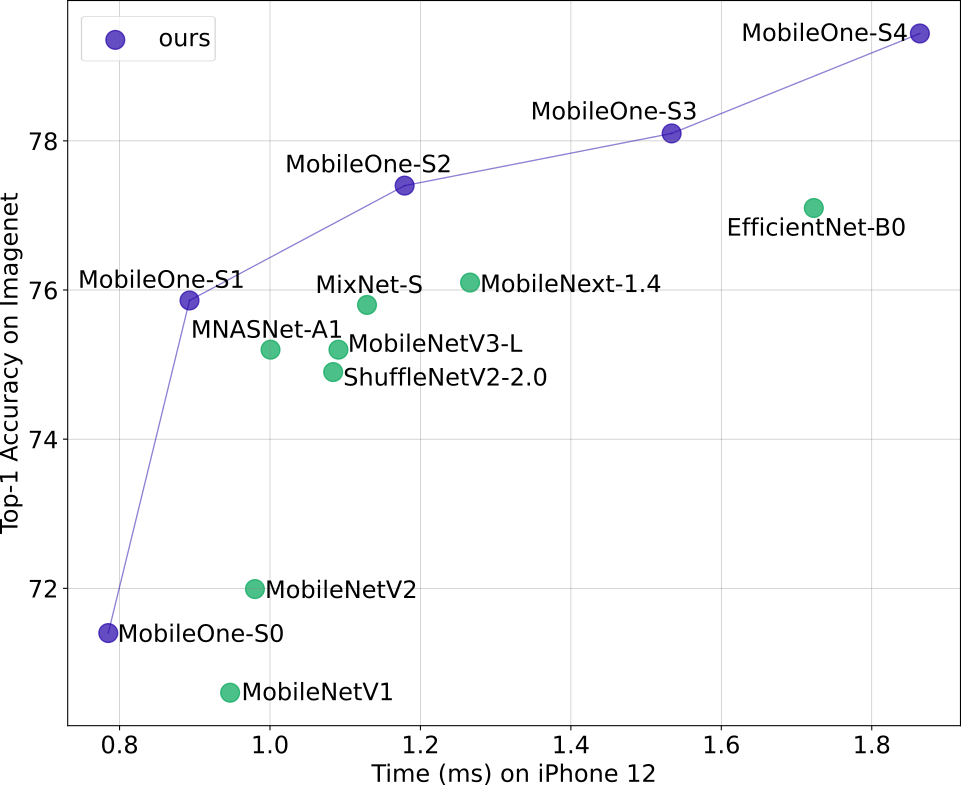


2021

2020




2019
-
 Towards Geometric Understanding of MotionUniversity of Tuebingen Tuebingen, 2019
Towards Geometric Understanding of MotionUniversity of Tuebingen Tuebingen, 2019 -
Unsupervised video segmentationSep 2019US Patent 10,402,986



2018


2017
-
Seeing Skin in Reduced CoordinatesIn IEEE International Conference on Automatic Face & Gesture Recognition (FG), Sep 2017

2016
-
 Interactive gaze driven animation of the eye regionIn International Conference on Web3D Technology, Sep 2016
Interactive gaze driven animation of the eye regionIn International Conference on Web3D Technology, Sep 2016

2015
-
-
Gaze driven animation of eyesIn ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Sep 2015
2012
-
Implementation of 3D object recognition and trackingIn International conference on Recent Advances in Computing and Software Systems (RACSS), Sep 2012